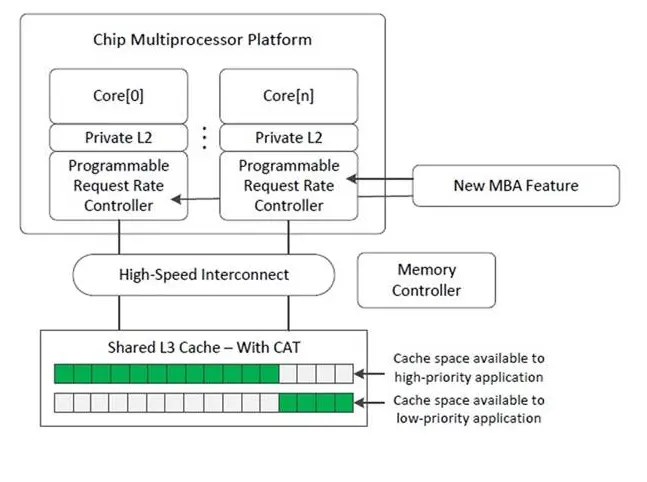
Intel RDT简介
RDT要解决的就是: cache level的资源隔离. 我们先看一下noisy neighbour问题.
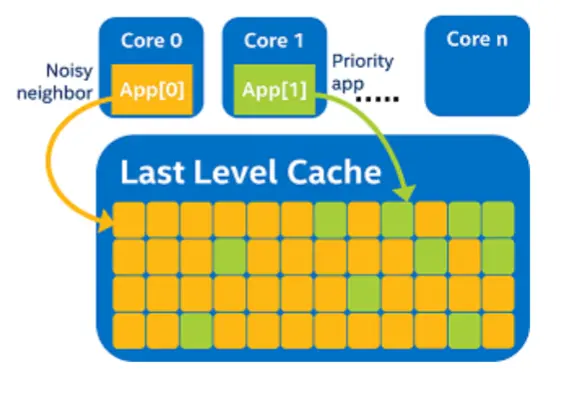
Noisy Neighbor问题
在目前Server的硬件架构中, 遵循以下规则:
- 每个logical core独享L1 cache (L1又被进一步地分为icache, dcache)
- 每个physical core(对应两个logical core)共享L2 cache
- 每个socket的core共享L3 cache
这就有可能引发noisy neighbor问题.
如下图, 分别有两个application, 由于L3是共享的, 同时遵循"先到先得"的原则, App[1]只有少量的L3 cache可以利用, 这对于它的性能无疑是不利的.
RDT分为5个功能模块: Cache Monitoring Technology (CMT) 缓存检测技术 Cache Allocation Technology (CAT) 缓存分配技术 Memory Bandwidth Monitoring (MBM) 内存带宽监测 Memory Bandwidth Allocation (MBA) 内存带宽分配 Code and Data Prioritization (CDP) 代码和数据优先级
下面主要介绍一下CAT和MBA的机制.
Cache Allocation Technology (CAT)
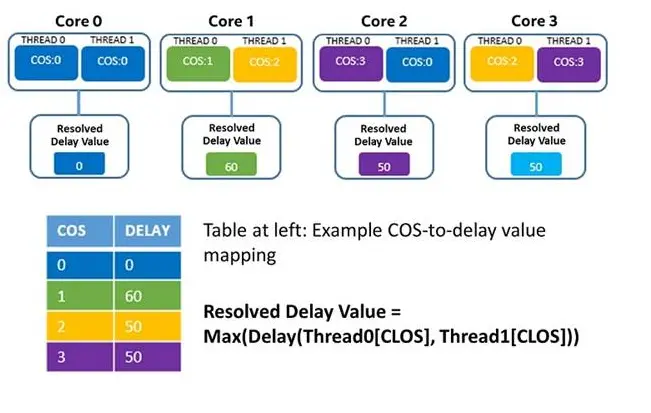
RDT中定义了clos的概念, 可以将它类比为cgroup中的group. 一个clos对应了一种hareware config(比如20% L3 cache). 通过将上层应用映射到这些clos, 来达到资源控制的效果.
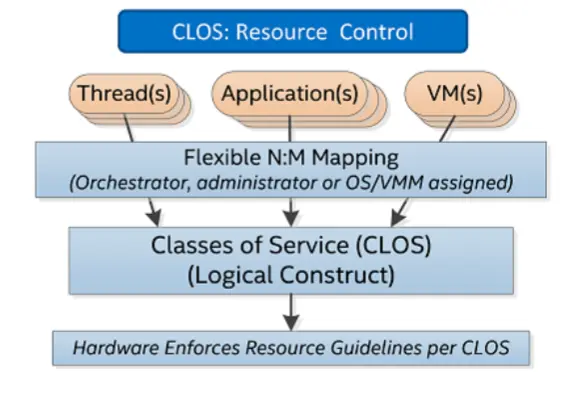
我们自底向上看一下RDT的实现机制.
首先, RDT使用bitmask来刻画clos所对应的cache资源.
下面这个例子中, clos[1]可以使用20%的L3 cache.
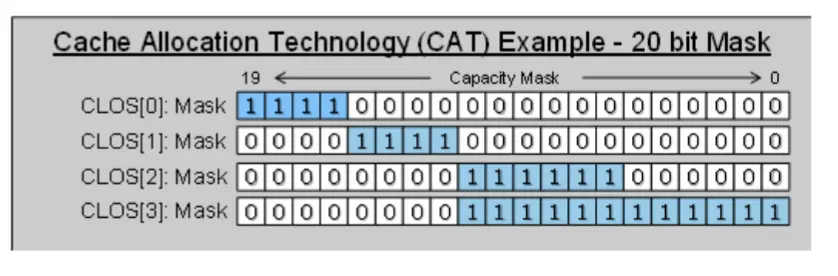
在硬件上, n个寄存器被用来存储clos->bitmask的映射关系.
从这一点上可以知道, 一台物理机所允许的clos是有上限的.
然后, 每个cpu内部都有一个特殊的寄存器, 用来存储对应的closid.
这样一来, 就完成了cpu -> bitmask的映射.
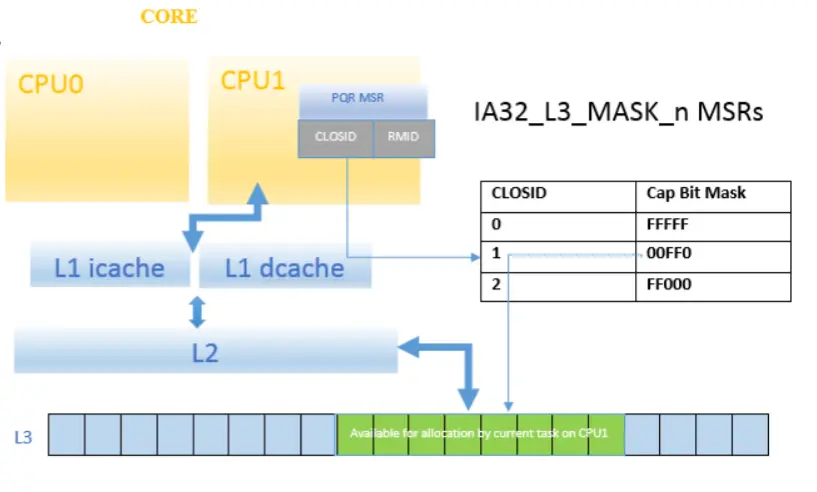
从上面的分析可以知道, 通过读写寄存器, 就能够完成CAT的功能. Intel提供了两种CAT的方式:
- kernel rdt support: 进程切换的时候, kernel会把procoss所属的closid更新到相应cpu的寄存器里. (需要修改kernel config)
- intel-cmt-cat: 除了kernel的方式, intel还提供了工具去直接读写寄存器. 由于缺少schedule的信息, 它只能将不同的cpu绑定不同的cache资源, 然后再将线程pin在上面, 从而达到一定程度的资源隔离. 好处是不需要重编kernel, 较为方便. 坏处是不能够支持线程迁移.
kernel rdt support
kernel使用resctl filesystem来作为暴露给userspace的接口. 使用之前, 需要先简单配置一下kernel
1. enable kernel config
- kernel v4.10 - v4.13 with kernel configuration option CONFIG_INTEL_RDT_A
- kernel v4.14+ with kernel configuration option CONFIG_INTEL_RDT
- kernel v5.0+ with kernel configuration option CONFIG_X86_RESCTRL
2. add kernel parameters (根据需要, 选择性添加就好)
rdt=cmt,mbmtotal,mbmlocal,l3cat,l3cdp,l2cat,l2cdp,mba
下面举例来说明一下resctrl的用法. step 1. mount resctrl
mount -t resctrl resctrl /sys/fs/resctrl
step 2. create clos
cd /sys/fs/resctrl
mkdir p0 p1
每个clos下面主要有三类文件:
- tasks: 表明所属于这个clos的task id.
- cpus: 表明所属于这个clos的cpu id.
- schemata: 表明了一种cache的配置.
一般来说, 有两种mode, tasks和cpus二选一配置就好了.
- task & schemata: 通过绑定task和schemata, 来完成资源隔离的目标. scheduler进行切换的时候, 对应cpu的closid也会发生变化.
- cpus & schemata: 通过绑定cpu和schemata, 来完成资源隔离的目标. 相当于把cpu里的closid固定住, 然后再将不同的thread pin再这些core上.
如果tasks和cpus都配置了, 且出现冲突的情况下(task实际运行的cpu和所属clos配置的cpu不一致), 以tasks所属的clos为准.
step 3. schemata config 首先, 每一个L1/L2/L3 cache都有对应的id, 比如说socket 0上的L3 cache index = 0, socket 1上的L3 cache index = 1.
/sys/devices/system/cpu/cpu*/cache/index*/id
然后, 我们将如下规则写入schemata. 等式左边是cache id, 等式右边是bitmask.
# echo "L3:0=3;1=c" > /sys/fs/resctrl/p0/schemata
# echo "L3:0=3;1=3" > /sys/fs/resctrl/p1/schemata
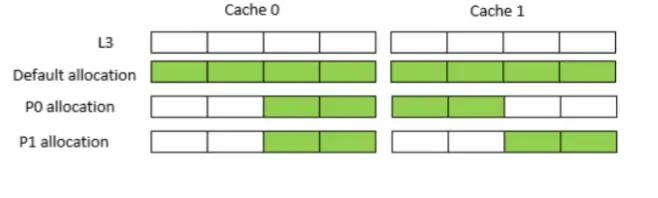
step 4. echo task
echo 1234 > p0/tasks
echo 5678 > p1/tasks
我还没有用RDT做过实验, 不知道"进程切换带来的closid切换"的overhead有多大, 会不会把task pin在某些core上会比较好.
intel-cmt-cat
占位(逃
Memory Bandwidth Allocation (MBA)
MBA的使用方式就不介绍了, 和CAT差不多, 主要是介绍一下它的硬件设计. Intel在L2和L3之间再加一个controller来控制bandwidth. 这个controller会根据用户给出的速率计算并加上一个delay. 需要注意的有两点
- 这个delay同样会影响L3 cache的latency.
- 假设有两个 不同bandwidth的process运行在同一个core上, bandwidth取较小值.